before_prompt_build Hook 分析报告 & 记忆系统优化建议
> 生成时间:2026-05-07
> 原始文档路径:~/.openclaw/workspace/openclaw-before_prompt_build-分析报告.md
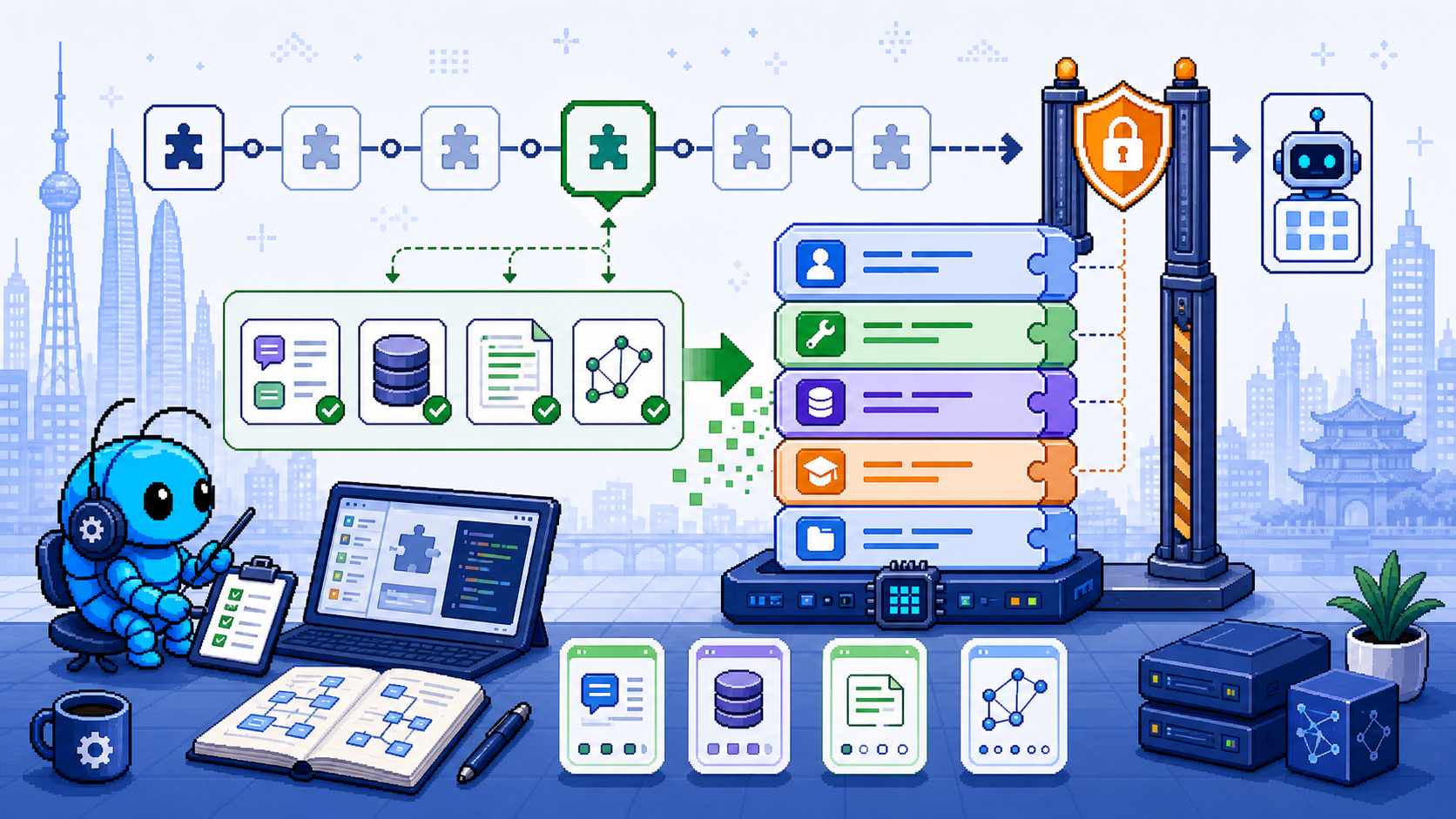
一、定位与性质
before_prompt_build 是插件钩子(Plugin Hook),不是内部钩子(Internal Hook)。它隶属于 OpenClaw 的 Prompt and Model Hooks 体系。
调用链路
before_model_resolve → override provider/model
agent_turn_prepare → 消费同 turn 注入的上下文
→ before_prompt_build → ← 所在位置:添加动态上下文或系统提示文本
before_agent_start → [兼容性保留,建议不用]
→ before_agent_run → 检查最终 prompt,决定是否阻止
→ [模型调用]
before_agent_reply → 短路返回合成回复
→ before_agent_finalize → 检查自然答案,请求额外一轮
agent_end → 观察完成状态
关键结论:before_prompt_build 是主模型调用前最后一个可以修改 prompt 的钩子,但它本身不控制是否发送——那是由 before_agent_run 决定的。
二、接受的事件对象
// 伪代码结构
{
type: "before_prompt_build",
context: {
prompt, // 当前用户输入
messages, // 已加载的会话历史消息
systemPrompt, // 当前系统提示
// ...其他环境上下文
}
}
三、可返回的结果
| 字段 | 作用 |
|---|---|
prependContext |
插入到对话上下文最前面 |
appendContext |
插入到对话上下文最后面 |
systemPrompt |
替换整个系统提示 |
prependSystemContext |
在系统提示开头追加内容 |
appendSystemContext |
在系统提示末尾追加内容 |
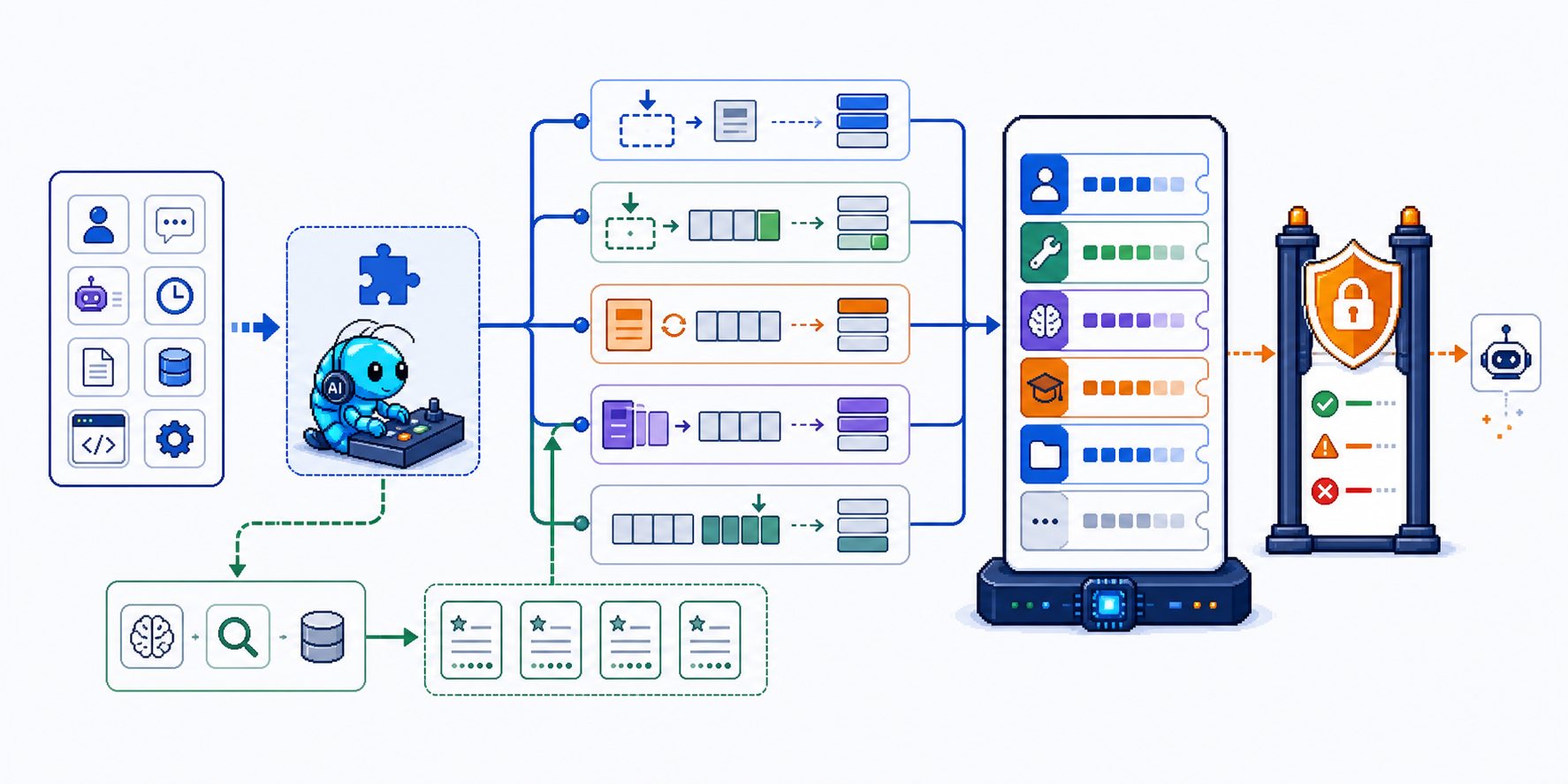
四、OpenClaw 现有记忆系统全貌
记忆来源(优先级从高到低)
├── Bootstrap 文件(每次 turn 注入)
│ ├── MEMORY.md ← 长期记忆,每次都注入
│ ├── SOUL.md / IDENTITY.md / USER.md
│ └── HEARTBEAT.md
│
├── Active Memory 插件 ← 主回复前主动搜索,blocking 方式
│ ├── queryMode: message / recent / full
│ └── promptStyle: balanced / strict / contextual / preference-only
│
├── memory_search 工具 ← 模型按需调用
│
├── Dreaming 系统 ← 后台将短期记忆晋升到 MEMORY.md
│
└── Daily Notes (memory/YYYY-MM-DD.md)
└── 今天/昨天的由系统自动加载,更早的按需读取
当前体系的短板
memory/YYYY-MM-DD.md日常笔记默认不自动加载,只有最近两天会加载,更早的需要模型主动memory_search- Active Memory 是 blocking 的,增加了用户可感知的延迟(即使配了 15s 超时)
MEMORY.md随时间膨胀,会导致上下文变大、压缩更频繁
五、优化记忆系统的三条路线
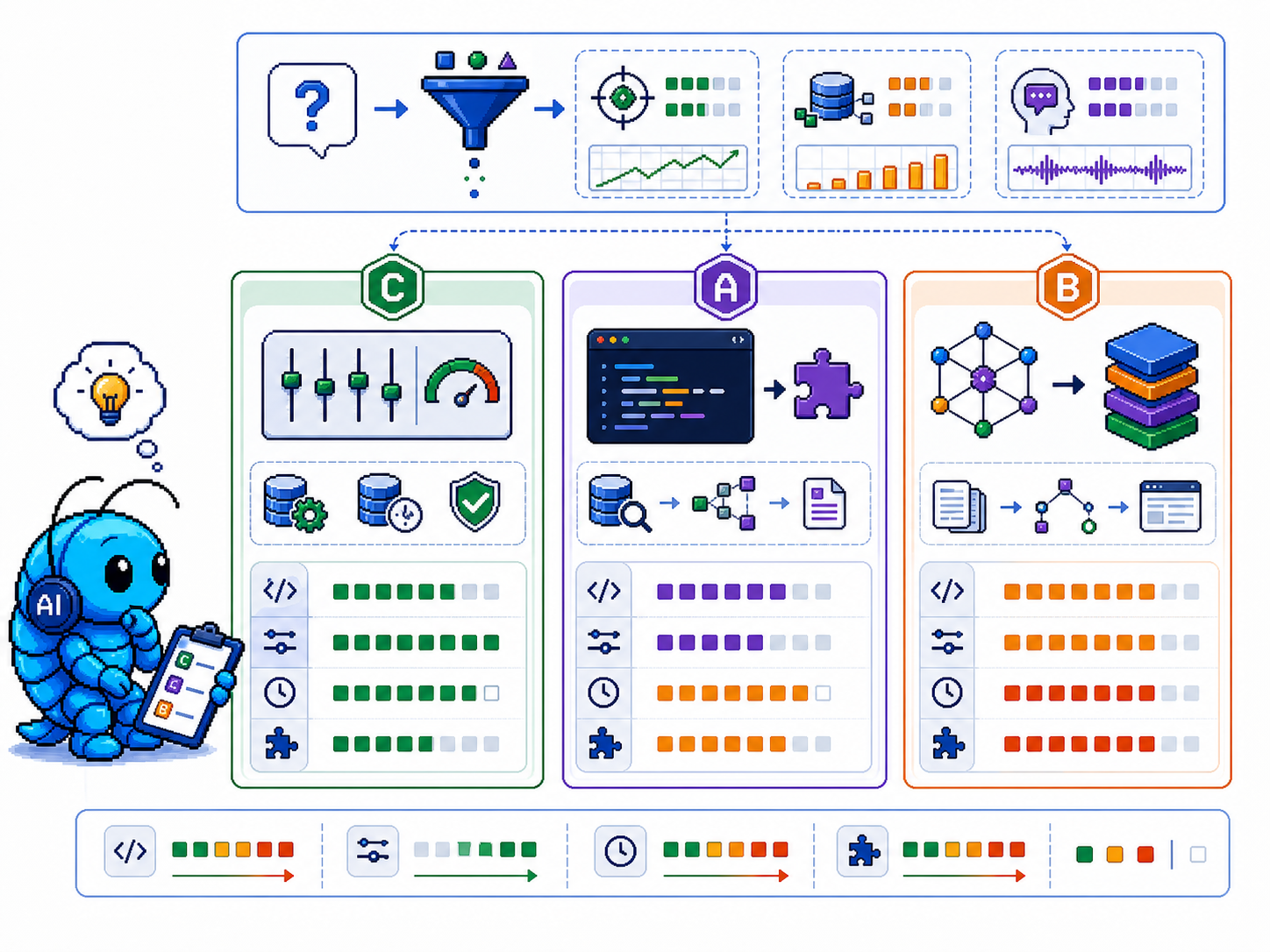
方案 A:用 before_prompt_build 做主动记忆注入(轻量级)
思路:在 before_prompt_build 里,根据当前 prompt 和 messages,调用 memory_search 查到最相关的记忆片段,通过 prependContext 注入。
用户消息 → before_prompt_build → memory_search → prependContext → 主模型回复
优点: - 非阻塞(相比 Active Memory 的 blocking sub-agent) - 不改变现有记忆文件结构 - 可以根据会话上下文动态决定注入哪些记忆
实现要点:
api.on("before_prompt_build", async (event) => {
const query = event.context.prompt; // 当前用户消息
const memories = await memorySearch(query); // 调用记忆搜索
if (memories.length > 0) {
return {
prependContext: "相关记忆:\n" + memories.join("\n")
};
}
}, { priority: 50 });
缺点:
- 需要自己实现 memory_search 调用
- 插件需要申请 allowConversationAccess: true 才能访问 messages
方案 B:基于 Context Engine 的 systemPromptAddition(更深度)
思路:注册一个自定义 Context Engine,在 assemble() 阶段将记忆文件动态拼接到 systemPromptAddition 中。
优点:
- 与 OpenClaw 上下文组装管线深度整合
- 可控制 token 预算内的记忆量
- systemPromptAddition 跨平台/渠道复用
缺点:
- 需要实现完整的 Context Engine 接口(ingest / assemble / compact / afterTurn)
- 更复杂,但能力也更强
方案 C:改进现有的 Active Memory 配置(最安全)
思路:不一定需要写代码。调整 Active Memory 的配置可以达到类似效果:
- queryMode: "recent" 已包含最近几轮对话
- promptStyle: "preference-only" 更精准地召回个人偏好
- maxSummaryChars: 220 控制注入量
如果目标只是让记忆"更自然地出现",Active Memory 其实是设计良好的方案,只是需要调优。
六、方案对比
| 目标 | 推荐方案 |
|---|---|
| 最少代码,快速见效 | 调优 Active Memory 配置(方案 C) |
| 自定义注入逻辑,按需加载 | before_prompt_build 插件(方案 A) |
| 完全重构记忆召回管线 | Context Engine 插件(方案 B) |
七、后续行动建议
使用 before_prompt_build 之前,建议先明确:
-
解决什么问题? - 记忆召回不及时/不准? - MEMORY.md 膨胀导致上下文过大? - 希望模型在回复前"主动想起"某些事?
-
优先方案 C,用现有 Active Memory 验证效果,调参不动代码
-
如果方案 C 不足,再推进方案 A 或 B
报告生成:2026-05-07