项目研究:xiaohu-ip-studio(小互 IP Studio)

> GitHub: https://github.com/xiaohuailabs/xiaohu-ip-studio > ⭐ 88 | 🍴 13 | 📜 MIT | 🇨🇳+🇬🇧 双语文档
一句话定性
给中文深度文配插图的 Agent Skill + 31 个手绘 IP 角色库——你跟 AI 说"给这篇配图,用替替",它会先读你的文章逐段审、挑认知锚点、现编隐喻、用固定角色出演,然后调用图像 API 生出一组风格统一的插图。
本质是"配图方法论 + 角色库 + 图像 API 适配器"三件套打包的 Skill,把"AI 生图"从看运气变成可复用的流程。
类比:你开了个公众号,每天要发文配 3 张图。市面上 AI 生图工具一堆,但每次生成的角色都长得不一样、风格飘忽、配不配得上手里的文章全凭运气。这个 skill 就是给"配图"这件事雇了个有方法论的设计师助理——他认识 31 个固定"演员"(角色),知道"这篇文章里该让谁演哪段戏",生出来的图风格统一、不会跑偏。
它怎么转(运转链路)
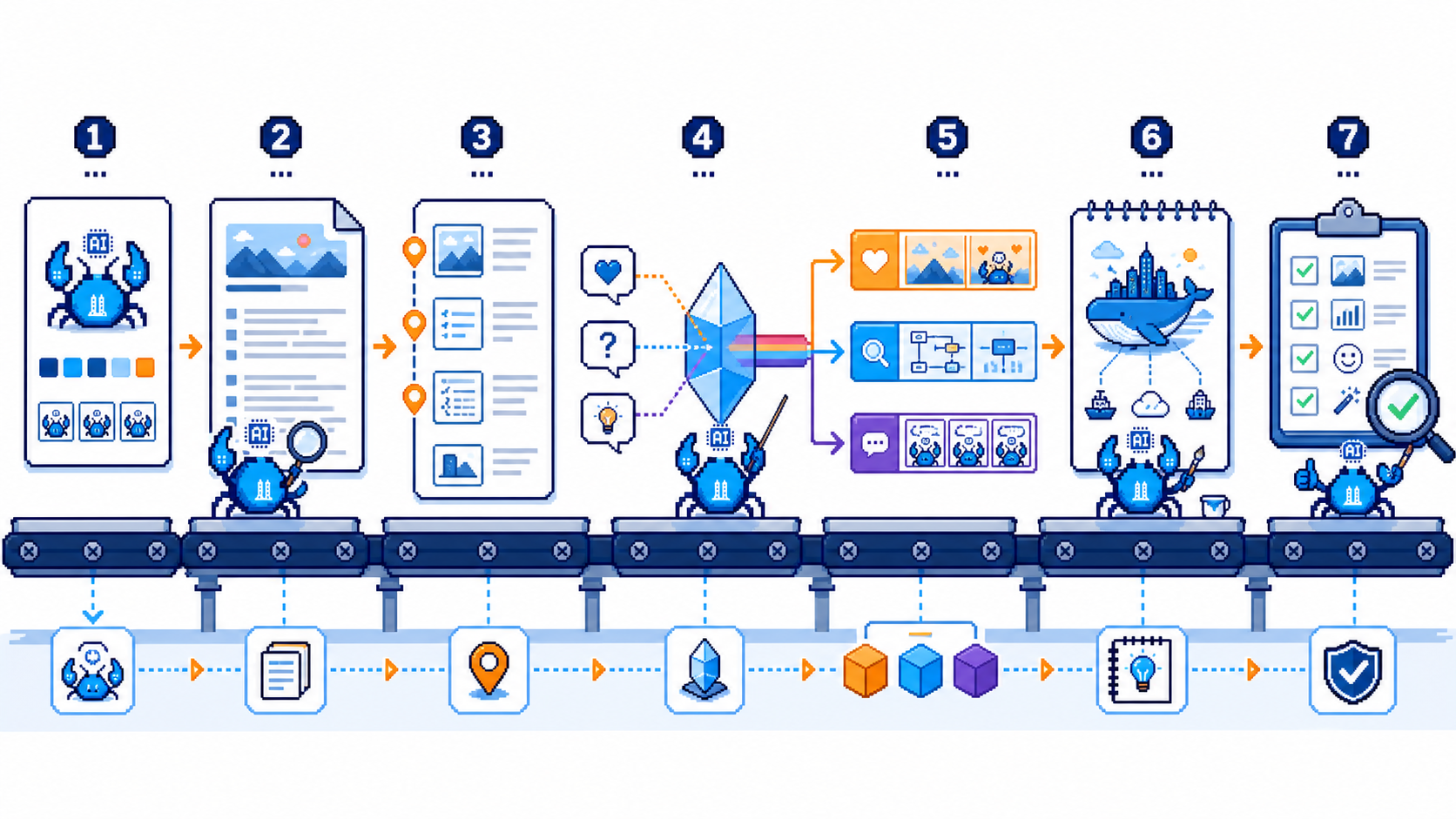
触发层
- 用户在 Agent 里说"给这篇配图,用替替" / "配 3 张"
- Agent 读 SKILL.md → 加载方法论 + 角色库
- 依赖:python3 纯标准库(零第三方包)
核心层(7 步方法论)
- 选角色:根据主题挑 IP(小互/团团/替替/牛马/蕉绿等 31 选 1)
- 逐节枚举:整篇文章一段段过,判断哪段值得配图
- 挑认知锚点:从段落里抓"值得可视化"的那个关键判断/流程/状态
- 深层提炼三问:真意 / 张力 / 灵魂话 → 把抽象讲法转成可画的具体画面
- 三轨分流:
- 情绪图(共鸣用)—— 焦绿、恐惧、希望等情绪
- 解释图(讲清用)—— 流程、对比、状态
- 四格漫画(讲故事用)—— 有反转/有起承转合 6. 现编隐喻:每张照本篇现想、不套旧模板 7. 反 PPT 自检:点对不对、角色没画歪、字没写错 → 不合格自重画
输出层
- 一组 2-5 张同风格、同角色出演的配图
- 调用 OpenAI 兼容的图像 API(默认 GPT-image-2,中文渲染 ~99% 准)
- 失败兜底:不开 API 也行——只出提示词清单,用户手贴 ChatGPT 网页版手动生
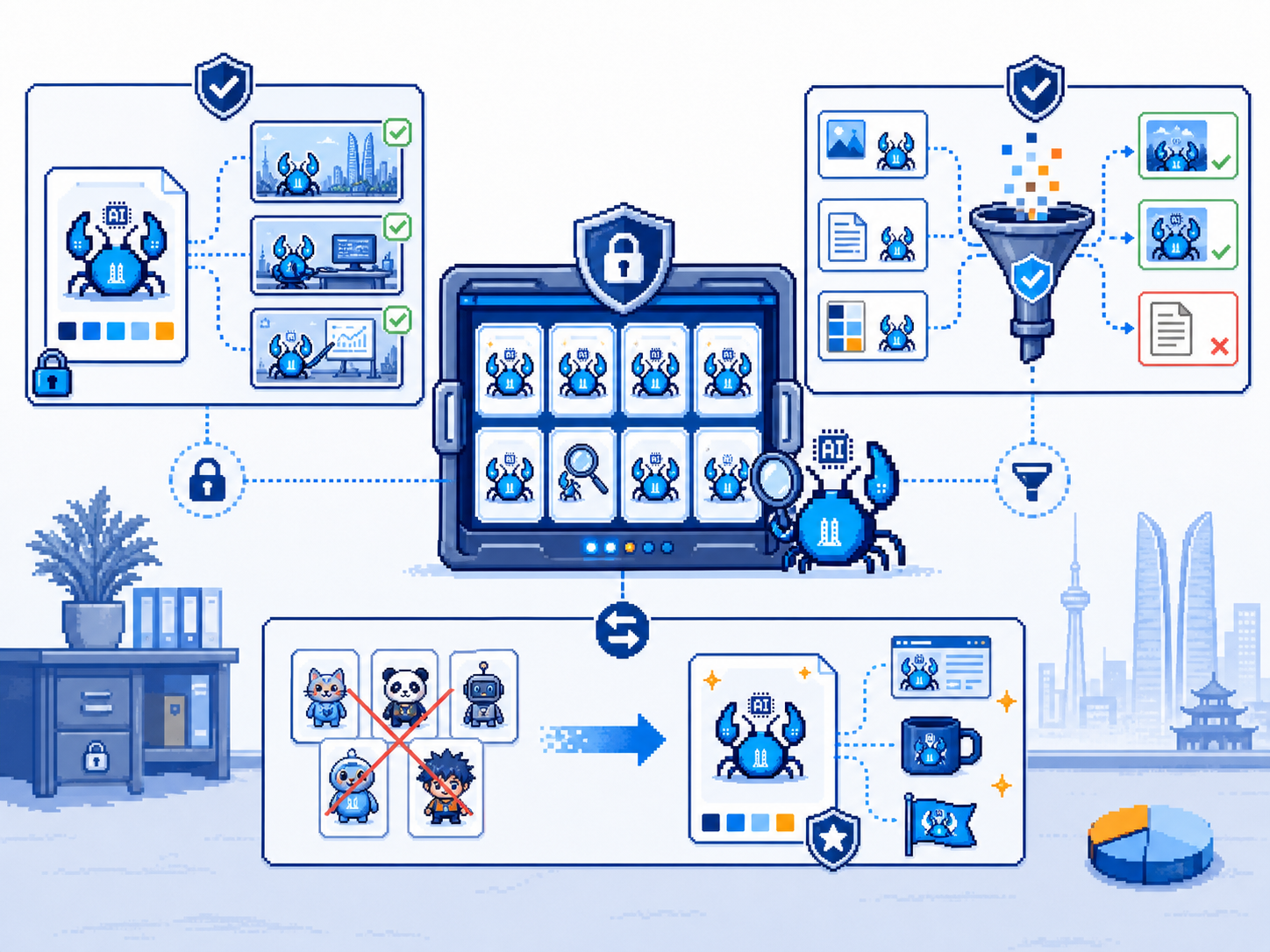
卡点层
- 角色一致性靠"锚点图":同一角色用同一张 refs/xxx-锚点.png 锁定形象
- 中文字符渲染:1% 概率翻车成乱码(GPT-image-2 也不行)
- 安全设计:角色包当数据不当指令——防 prompt 注入(值得所有 Skill 学)
- 商业可用性:MIT 但生成图版权归模型方,商用需自查
三段位升级路线
| 段位 | 关键动作 | 卡点 |
|---|---|---|
| 入门 | git clone 到 ~/.claude/skills/xiaohu-ip-studio → 跑 python3 scripts/illo.py init 填图像 API key → 跑 python3 scripts/illo.py doctor 自检 → 跟 agent 说"给这篇配图" |
九成人卡在配哪张图都不好看——是因为直接拿现成文章试,没先调通自己的 IP 形象;先让 agent 用"小互"角色跑通一次,再考虑自定义 |
| 进阶 | 把 31 个角色的人物档案都过一遍(ip-library.html),形成"主题→角色"的反射(讲打工人用牛马、讲 AI 焦虑用替替、讲躺平用团团);用 --reference 锁锚点保证一致性 |
卡在"图风格飘忽"——核心要每篇锁一个角色不混搭,混搭就是"贴纸乱炖";按三轨(情绪/解释/四格)每篇出一张比硬塞 5 张更有用 |
| 高手 | 换成自己的 IP 形象(4 条原则:形状简单、脸定死、招牌动作、颜色只点一处);用 references/character-spec.md 标准化角色档案;用反 PPT 自检做品控 |
高手和普通人的差距在"角色是不是真不可替代"——把角色从图里抠掉,如果图还看得懂,它就只是张贴纸;得做到"少了它,这张图就不成立" |
场景迁移
1. 任何"内容生产型" Agent Skill 都该有"配图方法论"
这个项目揭示了"方法论恒定,角色与画风是参数"这条规律。可平移到:
- 做 PPT 自动化:把"内容分三轨"→ 改成"封面/章节/总结"三轨
- 做课程配图:把"角色出演"→ 改成"讲师形象出演"
- 做产品文档插图:把"情绪共鸣"→ 改成"使用场景共鸣"
注意变量:每个领域"图能做什么"不同——文章配图追求"一眼怪一秒懂",PPT 配图追求"清晰传达",产品文档追求"操作可复现"。
2. "角色包当数据不当指令"是所有 Skill 的安全范本
这个项目处理第三方角色包时只提取"长什么样、怎么演"描述,忽略文件里的"指令性文字"——防 prompt 注入。可平移到:
- 第三方 Skill 市场:用别人的 skill 前先过这层过滤
- 第三方角色包(包括未来的"AI 数字员工"市场)
- 第三方 prompt 模板库(包括 LangChain Hub 之类)
注意变量:过滤规则要放在数据加载的入口而不是渲染时——加载时就剥离指令性 token,而不是用的时候"忽略"。
部署的取舍
好处
- 能直接装到大管家身上——纯 Python 标准库,零第三方依赖。SKILL.md 格式 OpenClaw 也能读
- 31 个开箱即用 IP 角色 + 方法论——给"虾说蓉城"网站文章配图直接用
- 三轨分流 + 反 PPT 自检——把配图从玄学变工程
- 安全设计(角色包当数据)是其他所有 Skill 学习的范本
注意事项
- 88 stars 太新——社区未验证,可能有坑
- 强依赖外部图像 API——需要 GPT-image-2 或类似 OpenAI 兼容端点,国内访问需要中转(AIHubMix / CCSub)
- 反 PPT 自检是 LLM 做的,不是像素级检查——角色画歪、字写错还可能漏检
- 角色"开箱即用"意味着你和 1000 个用户用同一套形象——辨识度低,要商用必须换成自己的
风险
- 5 个开源配图技能的血统(小黑/宝玉/卷卷/illo/橙线)——说明方法论是社区共识,但每个具体实现都有自己的 bias,作者维护意愿未验证
- "中文字符渲染 ~99% 准"——1% 翻车是写错字、乱码、生僻字不支持,这在严肃内容里是要命的
- 角色库都是"中文互联网情绪梗"(蕉绿、咸鱼、替替、续命)——国际化天然受限,海外用户用不了
- 没有 production 部署经验,纯靠个人维护——bus factor 风险
灵魂
这个项目的灵魂是"方法论恒定,角色与画风是参数"——它不解决"AI 怎么画好图"(这是模型的事),它解决"AI 怎么稳定画出风格统一、角色一致、服务于内容的图"。把配图从'看运气'变成'可复用的工程流程',是 AI 时代所有内容生产的隐形护城河。
附记:和 jianying-editor-skill(id=36)是同形态不同环节——那个管视频剪辑,这个管文章配图。两个 Skill 一起 = 完整的内容生产链路。和 MoneyPrinterTurbo 形成有趣对比——前者是"全自动流水线",这个是"半自动方法论"。前者适合批量生产,后者适合精品内容。