项目研究:SAG(Zleap-AI/SAG)
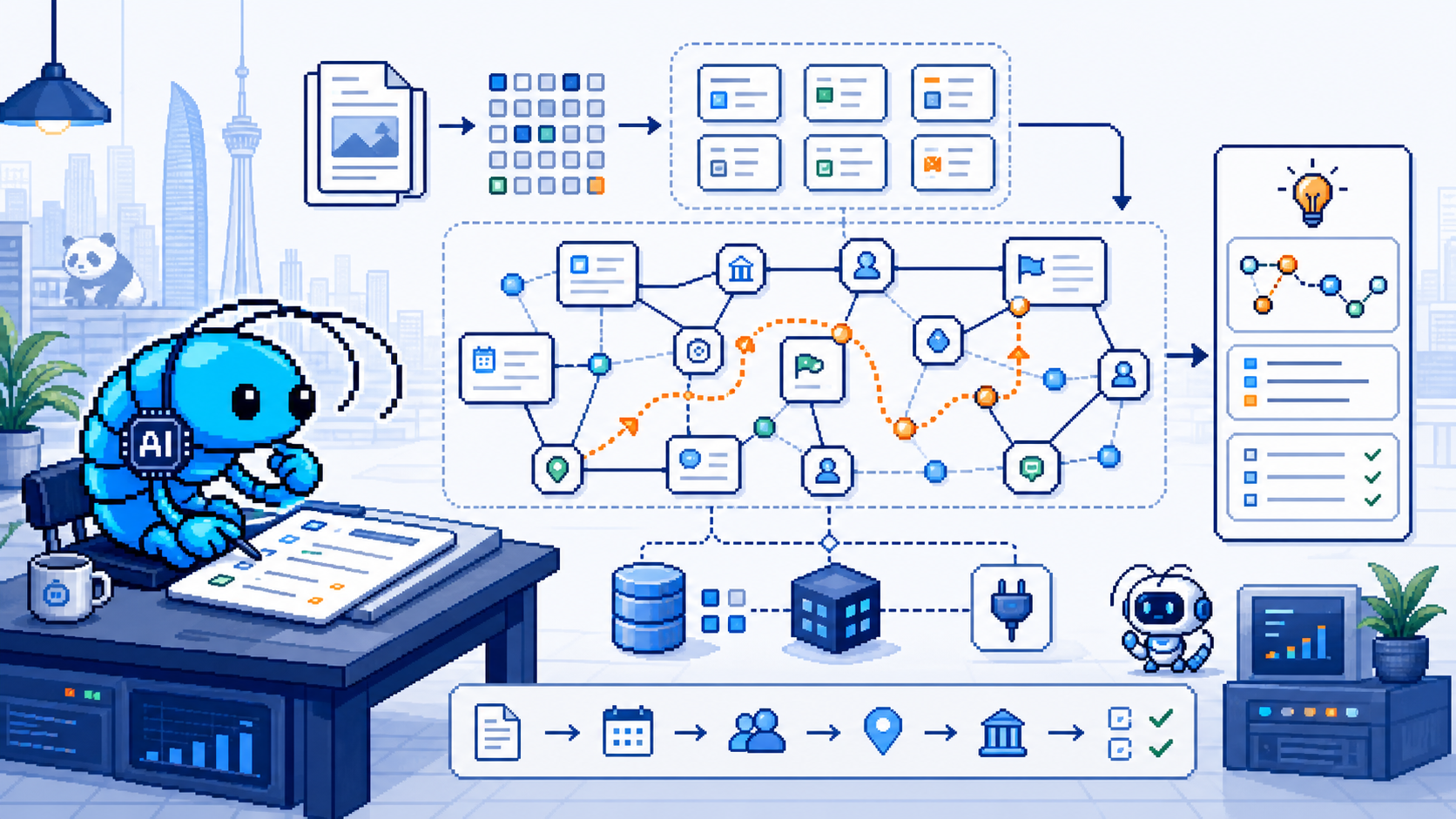
> 一个用"事件-实体"轻量结构替代传统向量检索的 RAG 工作台,多跳问答 Recall@2 比 HippoRAG 2 高 11 个点。
「这是什么」一句话定性
一个把"事件-实体"当成 RAG 索引核心结构的文档检索工作台——比传统向量检索更适合多跳问答,本地跑、ChatGPT 式对话、能直接当 MCP 工具被 Agent 调用。
仓库位置
| 项目 | 信息 |
|---|---|
| 仓库 | github.com/Zleap-AI/SAG |
| 论文 | arxiv.org/abs/2606.15971 |
| 协议 | MIT |
| 热度 | 较早期(2 PRs) |
| 默认端口 | WebUI 5173 / API 4173 |
核心创新:索引结构
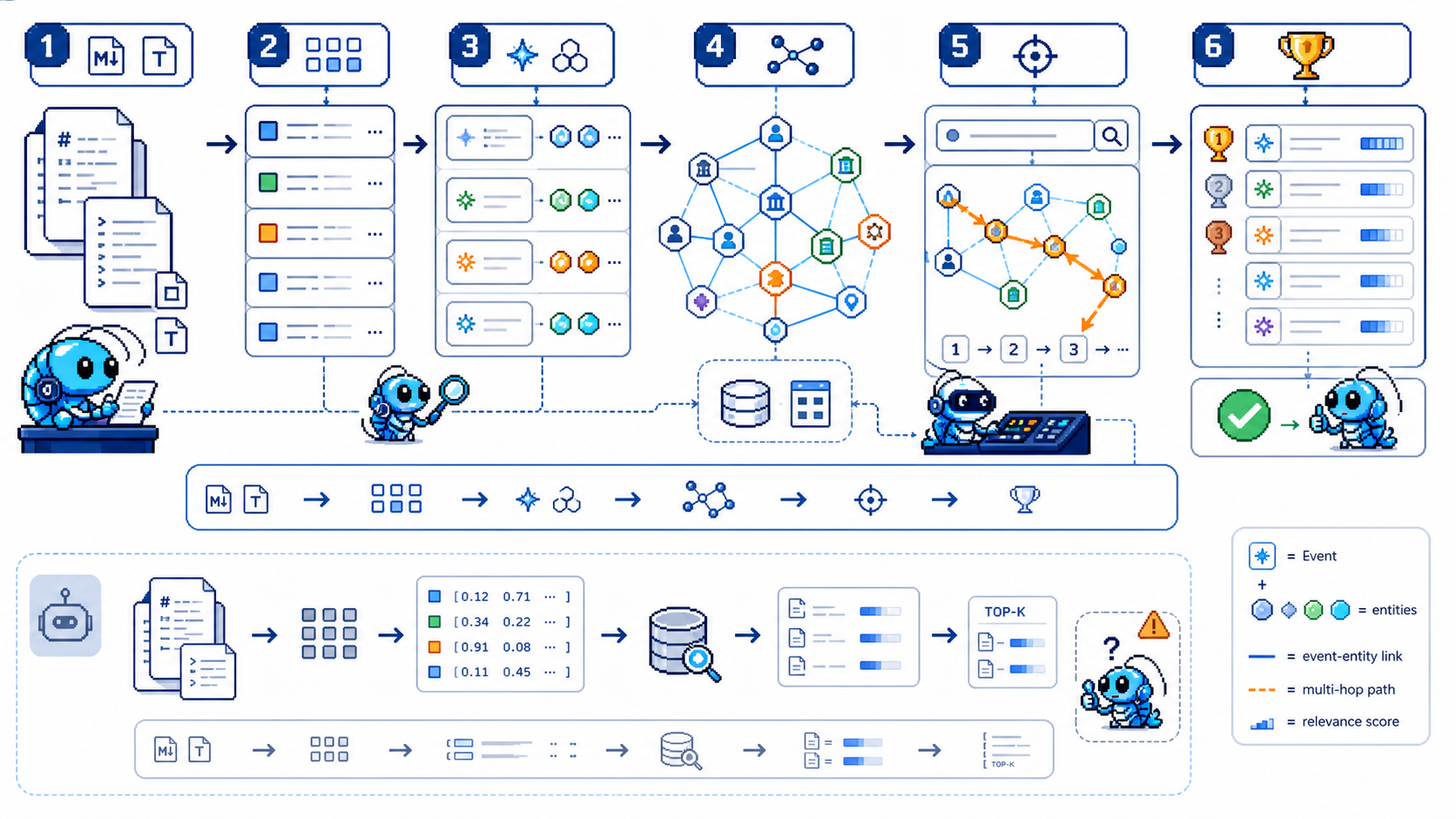
传统 RAG:
chunk → vector → top-k 相似度匹配 → 塞上下文给 LLM
痛点:多跳问答容易挂、上下文又长又乱
SAG 的索引结构:
chunk → event (每个 chunk 抽一个"完整语义事件")
chunk → entities(每个 chunk 抽多个命名实体)
event ↔ entities(多对多关系)
检索时:从匹配的 event 出发 → 沿 entity 关系做多跳扩展
类似生活比喻:传统 RAG 是在档案柜里翻相似纸条;
SAG 是建立"人-事-物"关系网,从一个人能跳到他干过的事
Benchmark 表现
在 HotpotQA / 2WikiMultiHop / MuSiQue 上,配置统一为 bge-large-en-v1.5 + qwen3.6-flash:
| 指标 | HippoRAG 2 | SAG | 提升 |
|---|---|---|---|
| 平均 Recall@2 | 68.14% | 79.30% | +11.16 pp(+16.4%) |
| MuSiQue Recall@5 | 65.13% | 80.04% | +14.91 pp |
| MuSiQue Recall@5 (换 NV-Embed-v2) | — | 81.71% | 增益主要来自结构 |
「它怎么转」逻辑全景图
├─ 触发层
│ ├─ 你想对自己的项目文档做问答 → 走"上传→等处理→对话"主线
│ ├─ 你在调试 RAG pipeline 想看每一步走了什么 → 走"Search Trace + Raw Logs"
│ ├─ 你想探索文档里的实体和事件关系 → 走"Graph"标签页
│ └─ 你想让外部 Agent 直接对接这个知识库 → 走"MCP"标签页拿配置
│
├─ 核心层
│ 文档摄取管线(ingestion):
│ Markdown/TXT → 分块 → 向量化 → LLM 抽 event → LLM 抽 entities
│ → 建立 event ↔ entities 关系 → 入 PostgreSQL
│
│ 两种检索模式:
│ Fast 模式 → BM25 匹配 entities → SAG 多跳扩展 → qwen3-rerank 选 top-k
│ Standard 模式 → LLM 抽取 query entities → 多路召回 → LLM 重排
│
├─ 输出层
│ ├─ 文档处理视图:chunks / events / entities / embeddings 全部可检视
│ ├─ 对话视图:流式输出 + 编号引用 + 点编号跳转原文 chunk
│ ├─ 检索 Trace 面板:每一步检索的延迟、调用链实时可见
│ ├─ 原始日志:LLM/Embedding/Rerank 请求和响应都缓存
│ ├─ 知识图谱:拖拽/缩放/展开/双击看详情
│ └─ MCP 配置:每个项目独立一份,外部 Agent 可直接调
│
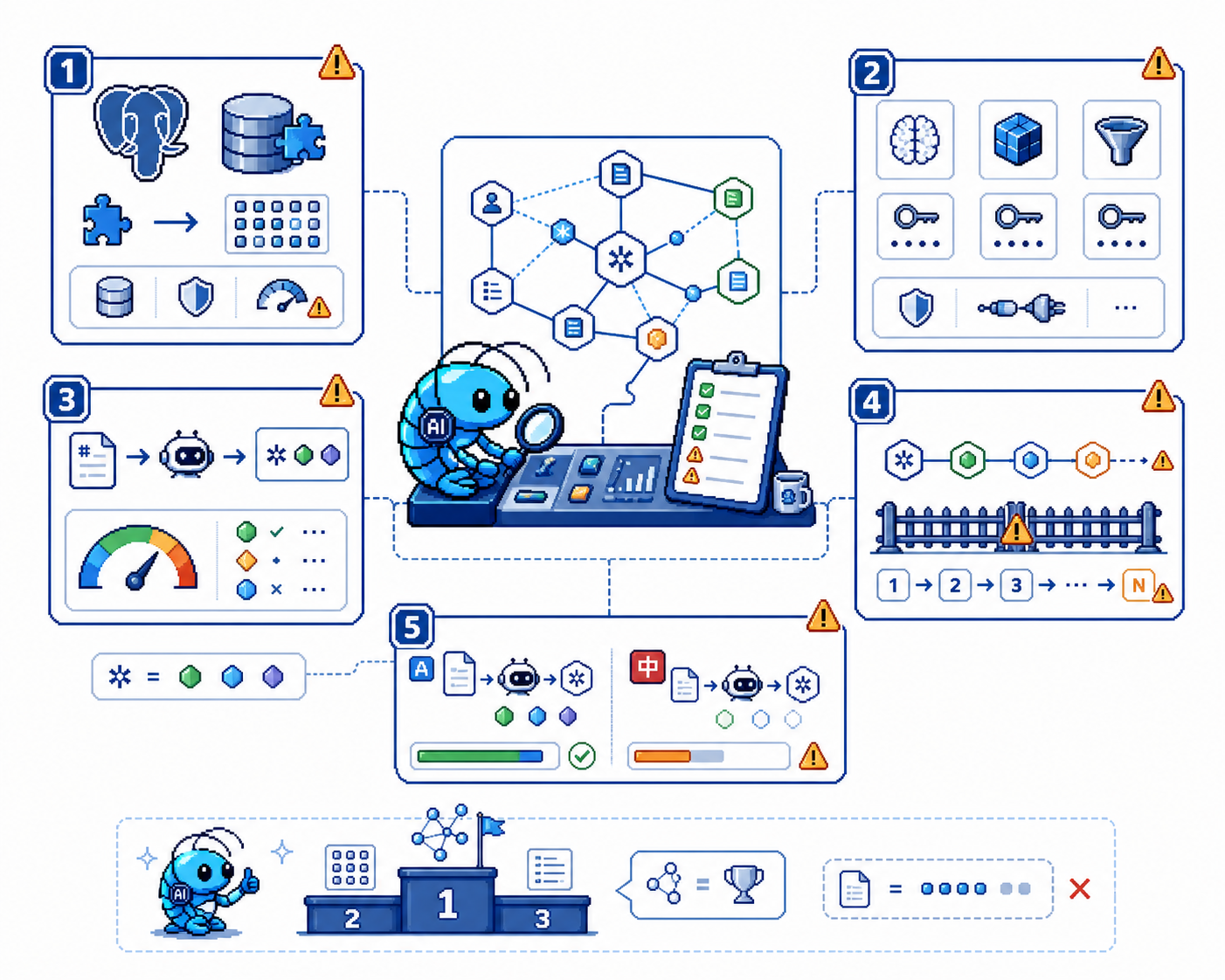
└─ 卡点层(新手最容易翻车的地方)
├─ PostgreSQL + pgvector 必装——pgvector 在 brew 上是独立 tap
├─ 模型 API 必须填——.env.example 里只有占位
├─ chunking 后的 event 抽取依赖 LLM 质量——抽偏了多跳就走偏
├─ 多跳不等于无限跳——SQL 多跳查询有跳数上限
└─ 论文里 benchmark 跑的是英文——中文文档抽取质量会打折
「怎么升级」三段位路线图
├─ 入门段(能用)
│ └─ docker compose up 一把梭:
│ - 默认 .env 跑通 → 上传 10 个 Markdown → Chat 标签页问 3 个问题
│ - 关键习惯:每个问题先看右边的 Search Trace,理解 SAG 怎么找到答案
│
├─ 进阶段(用好)
│ └─ 把生产文档喂进去:
│ - 拆项目(每个项目 = 一个独立知识库)
│ - Fast 模式日常用、Standard 模式调试用,对比看哪种问得更准
│ - 在 Graph 标签页找出"高频实体" = 你知识库的核心概念
│
└─ 高手段(用活)
└─ 把 SAG 当 MCP 工具嵌进自己的 Agent:
- 改造 event/entity 抽取 prompt,适配你的领域术语
- 自己加 rerank 模型 / 调 SQL 多跳跳数 / 加跨项目检索
- 高级玩家和别人最大的差距:他们把 SAG 当"可编程的检索内核"
「能用在哪」场景迁移
├─ 场景 1:任何"多跳问答"问题的通用解法
│ ├─ 技术文档库、产品手册、论文库、合同库、客服知识库
│ └─ 注意事项:单文档直接检索就够,别为"找一句话"上 SAG
│
├─ 场景 2:RAG 系统的"调试和压测"工具
│ ├─ SAG 自带 Search Trace + Raw Logs,是少有的开源 RAG 调试工作台
│ └─ 可以拿它当"标准答案",对比别的 RAG 系统在同样 query 下召回率
│
└─ 部署建议(如果装这个项目)
├─ 好处:本地 RAG 一把梭,MCP 直接对接 Agent
├─ 必要配置:Node.js 20+、PostgreSQL 17 + pgvector、LLM/Embedding/Rerank API
├─ 风险:LLM 抽取 event/entity 是成本大头;pgvector 大数据量下性能下降快
└─ 不适用:纯英文文档 + 实时性要求高的流式数据场景
技术栈
| 层 | 技术 |
|---|---|
| 前端 | React + Vite + Tailwind CSS |
| 后端 | Fastify + MCP TypeScript SDK |
| 数据 | PostgreSQL + pgvector + 全文搜索 + SQL 多跳 |
| 模型 | OpenAI 兼容 LLM / Embedding / Rerank |
核心模块(src/)
ingestion/— chunk/event/entity 抽取管线services/— 业务服务(搜索、对话)mcp/— MCP 集成,每个项目独立配置db/— PostgreSQL + pgvector + SQL 多跳observability/— Search Trace + Raw Logsai/— 模型调用抽象
一句话灵魂
"用'事件+实体'这种轻量结构替代沉重知识图谱,让多跳问答又快又准。"——这是 SAG 比传统 RAG 高明的地方,也是它敢说自己 SOTA 的底气。
本系列持续更新各类开源项目的解构研究,欢迎关注。